
The 8th of June, 2022, marked an important milestone for the MOSAICS project, as the AuDiET study collected data from its very first subject. But first things first.
What is AuDiET?
The acronym translates to the Latin word for “he/she/they will hear”, and it stands for “Audiometric Diagnostics and Error-based Treatment”. AuDiET is a clinical trial developed within the MOSAICS project and involving Enrico (ESR 4), Nikki (ESR 3) and other Radboudumc personnel, aiming to build a comprehensive, systematic and detailed dataset of clinical data for Cochlear Implant recipients. Specifically, the goal is to collect data before and after interventions, to achieve a deeper insight into how we can address poor outcomes with more accuracy than currently possible. This trial began to be conceptualised in February 2021 and both Enrico, Nikki and the supervision team have spent a considerable amount of effort in its design and implementation.
Why is AuDiET needed?
So far, the datasets that were available to us included either fitting data or detailed performance data, never both. AuDiET is designed to be as comprehensive as possible, with the additional goal of empowering future researchers to conduct exploratory analyses on the dataset and focus their efforts on more narrowly targeted clinical studies.
What does the study entail?
A study participant in AuDiET will undergo five visits. During four of these they will undergo a comprehensive test battery collecting detailed data about their speech comprehension. A large amount of the collected data concerns phoneme confusion: that is, investigating whether a subject is making specific errors (e.g., consistently mistaking a ‘f’ sound for a ‘v’ sound) systematically or whether their error patterns are more widespread.
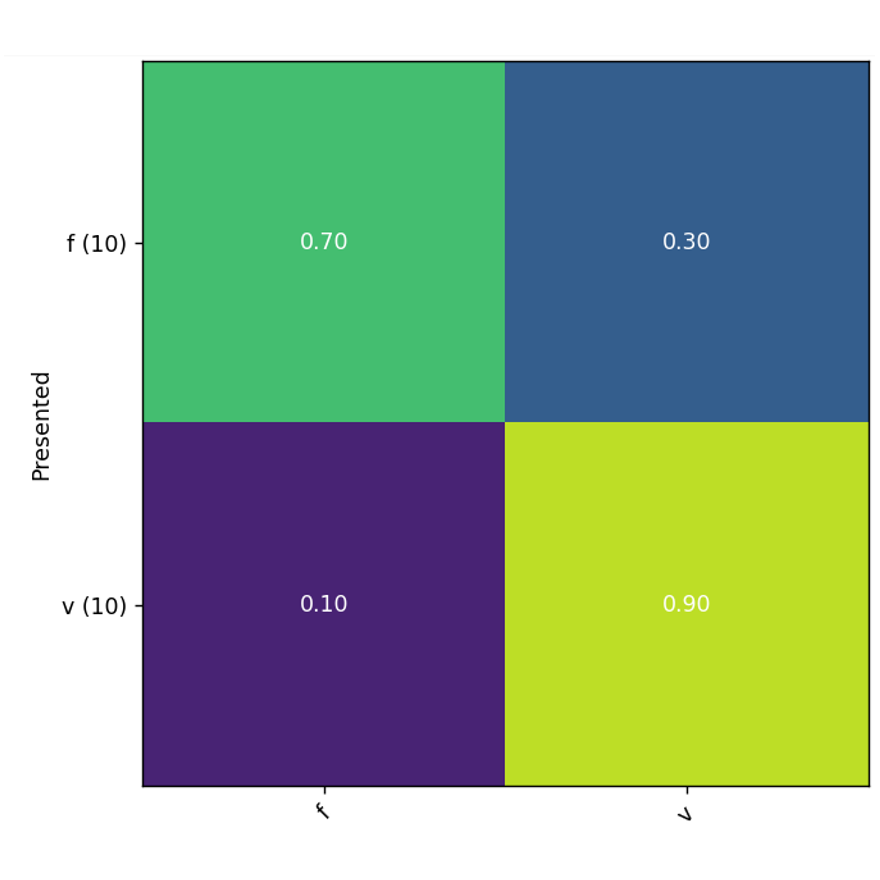
After the first of these visits, each subject will receive a targeted fitting intervention: that is, an adjustment of their sound processors aimed at addressing those errors that they appear to be making systematically. The fitting intervention falls under the purview of Enrico, whose research theme is cochlear implant fitting and how engineering might be applied to improve it. After an evaluation of this intervention, they will receive a targeted training intervention: that is, they will undergo audiologic training aimed at those same errors. The training intervention is guided by Nikki, whose research follows themes of clinical care and rehabilitation support. This intervention will be evaluated as well, and a final visit will track how much improvement is retained after some time without training.
Overall, we hope that AuDiET will help us shine a light on how fitting and training may influence the speech understanding of CI recipients. Artificial Intelligence and Machine Learning require comprehensive, structured data to be available in order to point at possible relationships of cause and effect. Having a dataset which includes fitting data as well as detailed speech recognition outcomes will help us make good use of these innovative techniques.
Keep following the MOSAICS project for future updates on AuDiET.